
3. Linear Models#
3.1. Introduction#
Linear models form one of the foundational pillars of statistical learning. Their simplicity, interpretability, and strong theoretical underpinnings make them an essential first step when analyzing data and building predictive models. Despite their apparent simplicity, linear models offer a surprising level of flexibility, especially when combined with feature transformations such as polynomials or radial basis functions.
In this chapter, we explore the principles and practical implementation of linear models. We begin with the generation of synthetic multivariate data to simulate a controlled environment for experimentation. We then dive into the manual computation of the Ordinary Least Squares (OLS) solution using matrix algebra, before comparing our results to those produced by well-established Python libraries such as statsmodels.
The chapter also highlights the importance of residual analysis for model diagnostics, offering tools to detect violations of assumptions like linearity, homoscedasticity, and normality. We further extend the linear model framework through input transformations, allowing us to capture non-linear patterns while preserving the model’s linear structure in parameters.
Finally, we introduce Ridge Regression, a regularized variant of linear regression, and examine its role in mitigating overfitting—particularly in scenarios involving multicollinearity or high-dimensional input spaces.
We now assume basic familiarity with matrix algebra and Python packages such as NumPy, Pandas, and Statsmodels.
We define the necessary imports as well as the pprint function.
import numpy as np
import pandas as pd
import seaborn as sns
import statsmodels.api as sm
from scipy.stats import probplot
from IPython.display import display, Math
from numpyarray_to_latex.jupyter import to_ltx
import matplotlib.pyplot as plt
plt.style.use(['seaborn-v0_8-muted', 'practicals.mplstyle'])
def pprint(*args):
res = ""
for i in args:
if type(i) == np.ndarray:
res += to_ltx(i, brackets='[]')
elif type(i) == str:
res += i
display(Math(res))
3.2. Generating Synthetic Multivariate Data#
We’ll create a dataset where Y depends on three features: X1, X2, X3.
The true data-generating process (DGP) is:
where \(\epsilon \sim \mathcal{N}(0, \sigma^2)\).
3.2.1. Exercise#
Create
Nobservations of(X1, X2, X3).Define true coefficients
beta_true.Generate noise and produce
Y.Store everything in a DataFrame for convenience.
3.2.1.1. Solution#
The following code generates a synthetic dataset for a linear regression problem with three explanatory variables (\(\mathbf X_1\), \(\mathbf X_2\), \(\mathbf X_3\)) and one target variable (\(\mathbf Y\)). It sets a random seed for reproducibility and defines true regression coefficients (beta_true) and a standard deviation for the noise (sigma_true). The explanatory variables are drawn from different distributions: uniform for \(\mathbf X_1\) and \(\mathbf X_2\), and normal for \(\mathbf X_3\). The true response Y_true is computed as a linear combination of the variables with the defined coefficients, and Gaussian noise is added to simulate observed values of \(\mathbf Y\). The resulting dataset, stored in a pandas DataFrame, includes the predictors and the noisy target variable, and the first few rows are displayed using df.head().
np.random.seed(123)
N = 200
sigma_true = 2.0
beta_true = np.array([5.0, 1.5, -2.0, 0.5])
X1 = np.random.uniform(-5, 5, size=N)
X2 = np.random.uniform(-10, 10, size=N)
X3 = np.random.normal(0, 2, size=N)
df = pd.DataFrame({'X1':X1, 'X2':X2, 'X3':X3})
Y_true = (beta_true[0]
+ beta_true[1]*df['X1']
+ beta_true[2]*df['X2']
+ beta_true[3]*df['X3'])
noise = np.random.normal(0, sigma_true, size=N)
df['Y'] = Y_true + noise
df.head()
| X1 | X2 | X3 | Y | |
|---|---|---|---|---|
| 0 | 1.964692 | 0.852719 | -3.510804 | 5.687964 |
| 1 | -2.138607 | -8.664511 | -0.697215 | 16.509223 |
| 2 | -2.731485 | 3.067297 | -0.385230 | -4.050829 |
| 3 | 0.513148 | 9.921727 | 0.898271 | -12.453060 |
| 4 | 2.194690 | 5.387947 | -0.290727 | -1.697682 |
3.2.2. Quick Data Inspection#
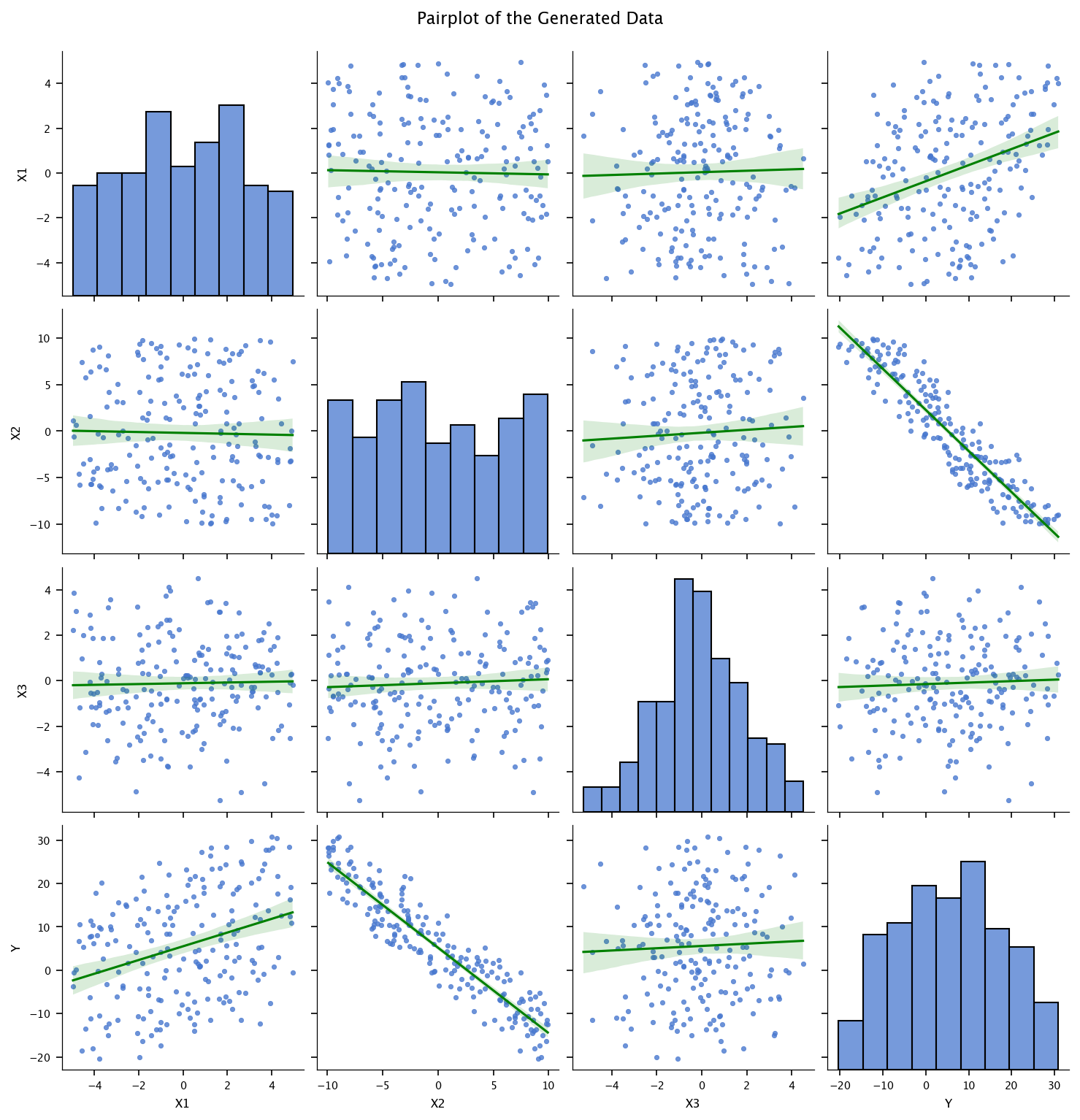
The following code performs exploratory data analysis on a DataFrame df. It first prints summary statistics of the DataFrame using df.describe(), which includes metrics like mean, standard deviation, min, and max for each numerical column. Then, it creates a pairplot using Seaborn with regression lines (kind='reg') to visualize pairwise relationships between all numerical features in the DataFrame. The regression lines are colored red, as specified in the plot_kws. A title is added slightly above the plot using plt.suptitle(), and finally, the complete visualization is displayed with plt.show().
print(df.describe())
sns.pairplot(df, kind='reg', plot_kws={'line_kws':{'color':'green'}})
plt.suptitle("Pairplot of the Generated Data", y=1.02)
plt.show()
X1 X2 X3 Y
count 200.000000 200.000000 200.000000 200.000000
mean 0.032708 -0.193044 -0.112239 5.572700
std 2.663947 5.907073 1.963533 12.473036
min -4.973119 -9.929356 -5.262876 -20.342999
25% -1.953937 -5.254828 -1.286318 -4.258475
50% 0.207716 -0.714124 -0.101728 5.417761
75% 2.181854 5.168943 1.206797 14.861563
max 4.953585 9.921727 4.501352 30.849943
3.3. Ordinary Least Squares (OLS) – Manual Computation Using Matrix Algebra#
We begin by specifying the standard linear regression model in matrix form:
where:
\(\mathbf{Y}\) is an \(N \times 1\) vector of observed responses,
\(X\) is an \(N \times p\) design matrix, which includes a column of ones to account for the intercept,
\(\boldsymbol{\beta}\) is a \(p \times 1\) vector of regression coefficients (including the intercept),
\(\boldsymbol{\epsilon}\) is an \(N \times 1\) vector of errors or residuals.
The goal of Ordinary Least Squares is to find the vector \(\hat{\boldsymbol{\beta}}\) that minimizes the sum of squared residuals. There is a well-known closed-form solution for this optimization problem, given by:
This formula provides the best linear unbiased estimator (BLUE) of the coefficients under standard assumptions (linearity, independence, homoscedasticity, and normally distributed errors).
In the following steps, we will:
Manually construct the design matrix \(X\), ensuring it includes a column of ones for the intercept.
Compute the estimated coefficients \(\hat{\boldsymbol{\beta}}\) using NumPy’s matrix operations, specifically
np.linalg.inv(...).Compare the computed estimates with the known or true values of the coefficients (
beta_true) used to generate the data.Validate our manual computation by comparing it to the output from the
statsmodelsOLS implementation.
X_mat = np.column_stack([
np.ones(N),
df['X1'].values,
df['X2'].values,
df['X3'].values
])
y_vec = df['Y'].values.reshape(-1,1)
print("X_mat shape:", X_mat.shape)
print("y_vec shape:", y_vec.shape)
X_mat shape: (200, 4)
y_vec shape: (200, 1)
XTX = X_mat.T @ X_mat
XTX_inv = np.linalg.inv(XTX)
XTy = X_mat.T @ y_vec
beta_hat_manual = XTX_inv @ XTy
beta_hat_manual = beta_hat_manual.flatten()
pprint("\\text{Manual OLS estimates}:", beta_hat_manual)
pprint("\\text{True coefficients}:", beta_true)
We see the manually computed OLS estimates are close to the true ones.
3.3.1. Comparison with statsmodels#
We’ll let statsmodels compute OLS, then compare the results in detail.
X_design_sm = sm.add_constant(df[['X1','X2','X3']])
model_ols = sm.OLS(df['Y'], X_design_sm).fit()
print(model_ols.summary())
beta_hat_sm = model_ols.params.values
print("statsmodels OLS:", beta_hat_sm)
print("Manual OLS:", beta_hat_manual)
OLS Regression Results
==============================================================================
Dep. Variable: Y R-squared: 0.976
Model: OLS Adj. R-squared: 0.976
Method: Least Squares F-statistic: 2657.
Date: Tue, 16 Sep 2025 Prob (F-statistic): 2.01e-158
Time: 13:31:42 Log-Likelihood: -415.03
No. Observations: 200 AIC: 838.1
Df Residuals: 196 BIC: 851.2
Df Model: 3
Covariance Type: nonrobust
==============================================================================
coef std err t P>|t| [0.025 0.975]
------------------------------------------------------------------------------
const 5.2043 0.138 37.720 0.000 4.932 5.476
X1 1.4772 0.052 28.497 0.000 1.375 1.579
X2 -1.9629 0.023 -83.872 0.000 -2.009 -1.917
X3 0.5243 0.070 7.446 0.000 0.385 0.663
==============================================================================
Omnibus: 1.025 Durbin-Watson: 2.042
Prob(Omnibus): 0.599 Jarque-Bera (JB): 1.117
Skew: -0.117 Prob(JB): 0.572
Kurtosis: 2.719 Cond. No. 5.91
==============================================================================
Notes:
[1] Standard Errors assume that the covariance matrix of the errors is correctly specified.
statsmodels OLS: [ 5.20431058 1.47721924 -1.96286883 0.52430039]
Manual OLS: [ 5.20431058 1.47721924 -1.96286883 0.52430039]
3.3.2. Observations#
The plain
Pythonresults matchstatsmodelsresults (modulo tiny numerical differences).Both are near the true coefficients
(5.0, 1.5, -2.0, 0.5).
3.4. Residual Analysis and Tests#
Once we have the fitted model, let’s analyze residuals:
residuals = model_ols.resid
fitted_vals = model_ols.fittedvalues
When evaluating the quality of a regression model, it is crucial to check whether the underlying assumptions hold. Two common residual diagnostic plots are:
The residuals vs. fitted plot
The QQ-plot.
We present both in details in the following sections.
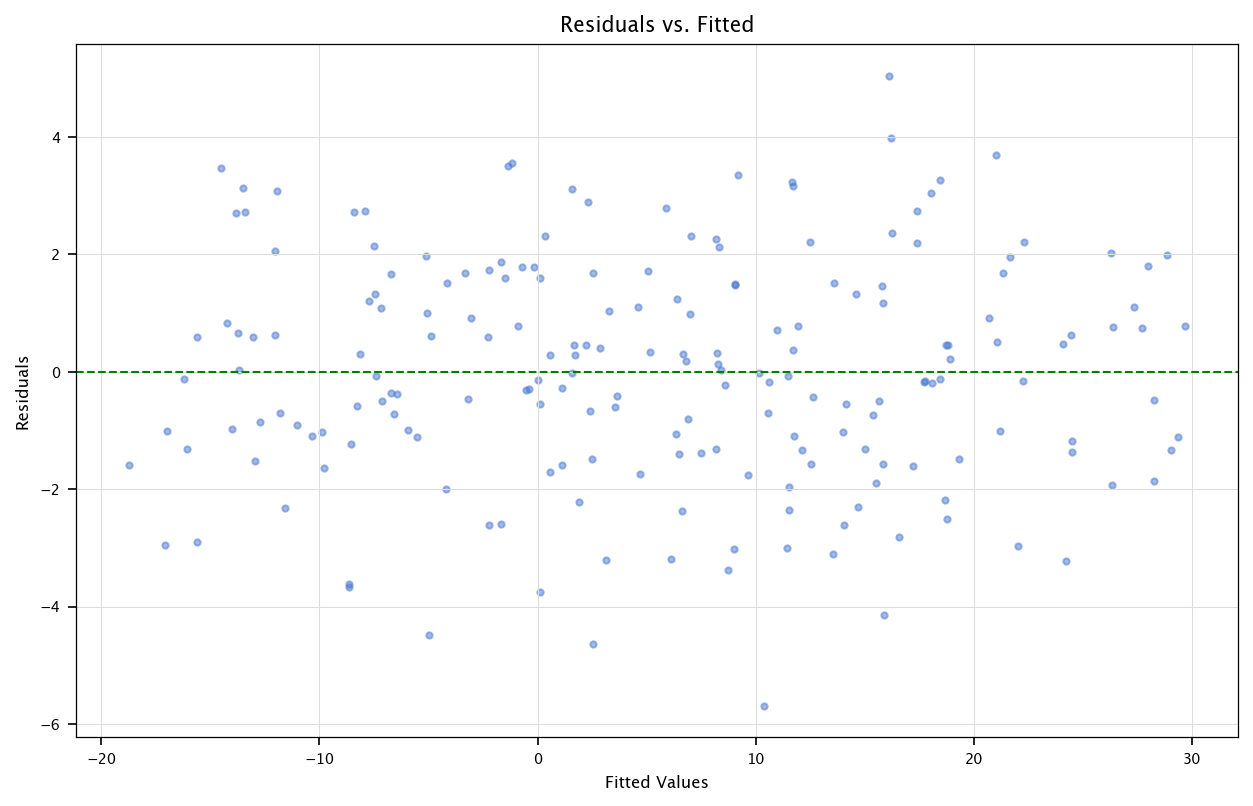
3.4.1. Residuals vs. Fitted Plot#
Purpose: This plot helps detect non-linearity and heteroscedasticity (unequal variance of residuals).
How it works:
The x-axis represents the fitted (predicted) values from the regression model.
The y-axis represents the residuals (errors).
Ideally, the residuals should be randomly scattered around zero, forming a homogeneous “cloud”.
Interpretation:
If a clear pattern (e.g., a curve) appears, it suggests non-linearity, meaning the model might be missing key features or transformations.
If the spread of residuals increases or decreases systematically, it indicates heteroscedasticity, meaning the variance of errors is not constant, which violates regression assumptions.
plt.figure(figsize=(10, 6))
plt.scatter(fitted_vals, residuals, alpha=0.5)
plt.axhline(y=0, color='green', linestyle='--')
plt.xlabel("Fitted Values")
plt.ylabel("Residuals")
plt.title("Residuals vs. Fitted")
plt.grid("on")
plt.show()
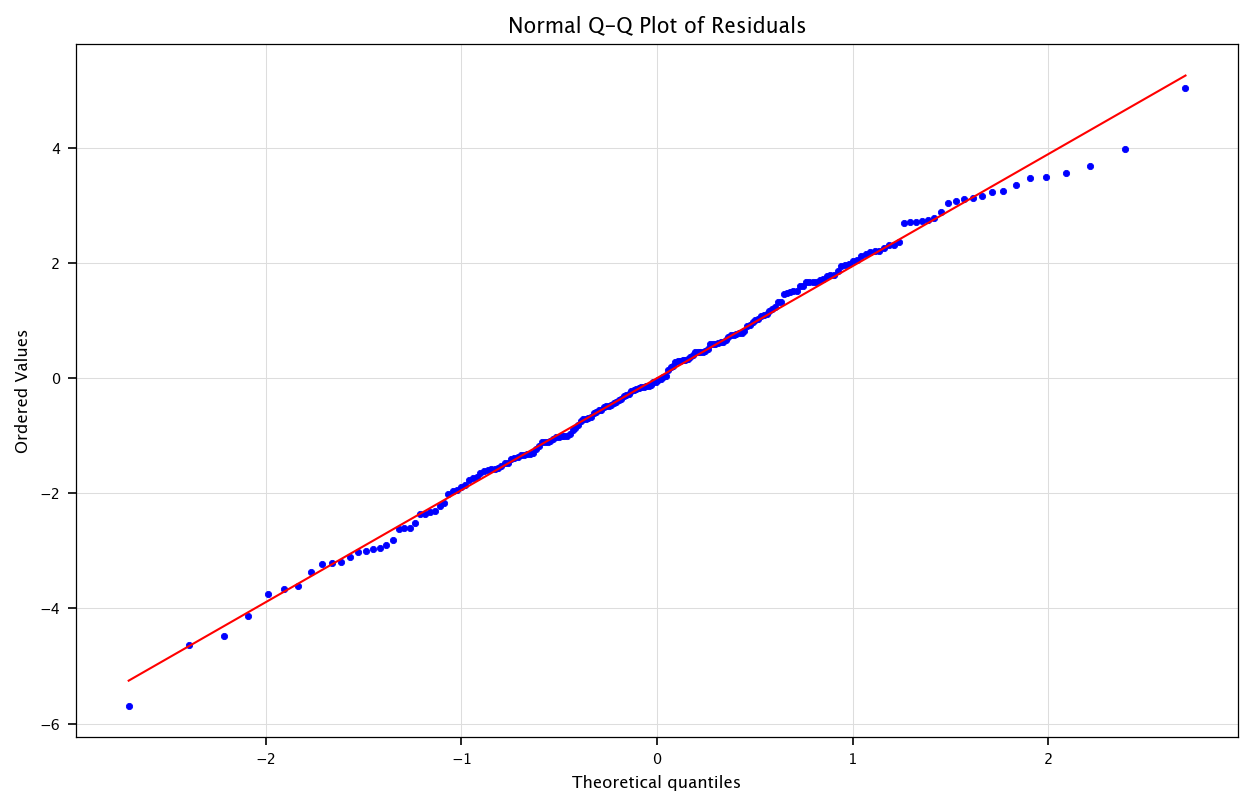
3.4.2. Normal Q-Q Plot (Quantile-Quantile Plot)#
Purpose: Checks whether the residuals follow a normal distribution, a key assumption in many regression analyses.
How it works:
The x-axis shows the theoretical quantiles (expected values under normality).
The y-axis shows the actual quantiles from the residuals.
If the residuals are normally distributed, they should closely follow a straight diagonal line.
Interpretation:
Straight-line alignment: Residuals are normally distributed.
Deviations (e.g., S-shape, heavy tails, skewed distribution): Suggests non-normal residuals, which might indicate missing variables, skewed data, or influential outliers.
plt.figure(figsize=(10, 6))
probplot(residuals, dist="norm", plot=plt)
plt.title("Normal Q-Q Plot of Residuals")
plt.grid("on")
plt.show()
3.5. Input Transformations - Polynomial Features#
When we talk about linear regression, we mean that the model is linear in parameters, not necessarily in the input variables \(X\). That is, the target variable \(y\) is modeled as a linear combination of parameters:
where:
\( \beta_0, \beta_1, \dots, \beta_n \) are the regression coefficients.
\( f_i(X) \) are functions of the input features (which can be non-linear transformations like squares or interaction terms).
\( \epsilon \) is the error term.
3.5.1. Example: Still a Linear Model#
Even if we introduce non-linear transformations of \(X\), as long as the model is linear in the parameters \( \beta_i \), it is still considered a linear model. For example:
This model includes a quadratic term (\(X^2\)), but is still a linear regression model because it remains a linear combination of the parameters \(\beta_0, \beta_1, \beta_2\).
3.5.2. What Would NOT Be a Linear Model?#
A regression model becomes non-linear in parameters if the parameters appear in a non-linear way. For example:
or
These models are non-linear in parameters because the relationship between \(y\) and the \(\beta\) coefficients is no longer a simple linear combination.
3.6. Why Use Polynomial Features in Linear Regression?#
Since linear regression allows us to use non-linear transformations of \(X\) while keeping the model linear in parameters, we can extend linear regression to capture more complex relationships.
3.6.1. Polynomial Feature Expansion#
Given original features \( X_1, X_2, X_3 \), we can introduce:
Squared terms: \( X_1^2, X_2^2, X_3^2 \) → captures curvature.
Interaction terms: \( X_1X_2, X_1X_3, X_2X_3 \) → captures relationships between variables.
By expanding the features in this way, we allow a linear regression model to approximate non-linear patterns in the data, making it more flexible while maintaining its interpretability.
3.6.2. Example#
A second-degree polynomial regression model:
This is still a linear model in parameters but now captures non-linear relationships in \(X\).
3.6.3. How to Implement Polynomial Features in Python#
In Python, we can generate polynomial features using sklearn.preprocessing.PolynomialFeatures.
from sklearn.preprocessing import PolynomialFeatures
poly = PolynomialFeatures(degree=2, include_bias=False)
X_poly = poly.fit_transform(df[['X1','X2','X3']])
print("Original shape:", df[['X1','X2','X3']].shape)
print("Polynomial shape:", X_poly.shape)
X_poly_mat = np.column_stack([np.ones(N), X_poly])
Original shape: (200, 3)
Polynomial shape: (200, 9)
The OLS is obtained using the same closed-form formulation:
XTX_poly = X_poly_mat.T @ X_poly_mat
XTX_poly_inv = np.linalg.inv(XTX_poly)
XTy_poly = X_poly_mat.T @ y_vec
beta_hat_poly_manual = XTX_poly_inv @ XTy_poly
beta_hat_poly_manual = beta_hat_poly_manual.flatten()
print("Manual OLS (polynomial) shape of beta:", beta_hat_poly_manual.shape)
pprint("\\text{beta\_hat\_poly\_manual}:", beta_hat_poly_manual)
Manual OLS (polynomial) shape of beta: (10,)
We can compare the results offered by statsmodel:
X_poly_sm = sm.add_constant(X_poly)
model_poly_sm = sm.OLS(df['Y'], X_poly_sm).fit()
beta_hat_poly_sm = model_poly_sm.params.values
pprint("\\text{Statsmodels polynomial OLS}:", beta_hat_poly_sm)
pprint("\\text{Manual polynomial OLS}:", beta_hat_poly_manual)
print("\nPolynomial OLS summary:\n", model_poly_sm.summary())
Polynomial OLS summary:
OLS Regression Results
==============================================================================
Dep. Variable: Y R-squared: 0.976
Model: OLS Adj. R-squared: 0.975
Method: Least Squares F-statistic: 872.4
Date: Tue, 16 Sep 2025 Prob (F-statistic): 2.13e-149
Time: 13:31:42 Log-Likelihood: -413.46
No. Observations: 200 AIC: 846.9
Df Residuals: 190 BIC: 879.9
Df Model: 9
Covariance Type: nonrobust
==============================================================================
coef std err t P>|t| [0.025 0.975]
------------------------------------------------------------------------------
const 5.0526 0.287 17.620 0.000 4.487 5.618
x1 1.4773 0.053 27.754 0.000 1.372 1.582
x2 -1.9646 0.024 -82.615 0.000 -2.012 -1.918
x3 0.5315 0.073 7.290 0.000 0.388 0.675
x4 0.0036 0.020 0.179 0.858 -0.036 0.043
x5 0.0054 0.009 0.571 0.569 -0.013 0.024
x6 0.0249 0.028 0.879 0.381 -0.031 0.081
x7 0.0037 0.005 0.803 0.423 -0.005 0.013
x8 0.0133 0.012 1.074 0.284 -0.011 0.038
x9 -0.0026 0.028 -0.095 0.924 -0.058 0.052
==============================================================================
Omnibus: 0.925 Durbin-Watson: 2.024
Prob(Omnibus): 0.630 Jarque-Bera (JB): 1.006
Skew: -0.090 Prob(JB): 0.605
Kurtosis: 2.703 Cond. No. 97.1
==============================================================================
Notes:
[1] Standard Errors assume that the covariance matrix of the errors is correctly specified.
3.6.3.1. Residual analysis and QQ-plot#
residuals_poly = model_poly_sm.resid
fitted_poly = model_poly_sm.fittedvalues
plt.figure(figsize=(10, 6))
plt.scatter(fitted_poly, residuals_poly, alpha=0.5)
plt.axhline(y=0, color='green', linestyle='--')
plt.xlabel("Fitted values (poly)")
plt.ylabel("Residuals")
plt.title("Residuals vs. Fitted (Polynomial Model)")
plt.grid("on")
plt.show()
plt.figure(figsize=(10, 6))
probplot(residuals_poly, dist="norm", plot=plt)
plt.title("Normal Q-Q Plot (Polynomial Model Residuals)")
plt.grid("on")
plt.show()
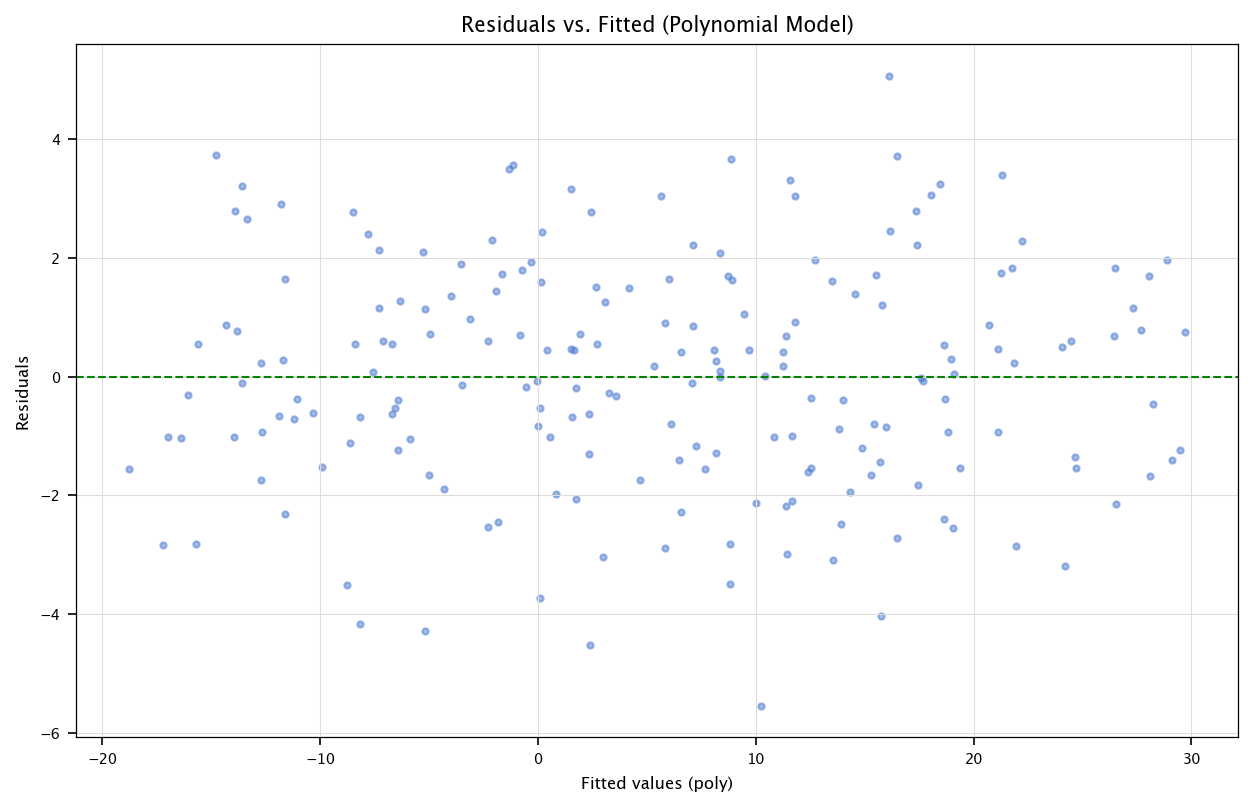
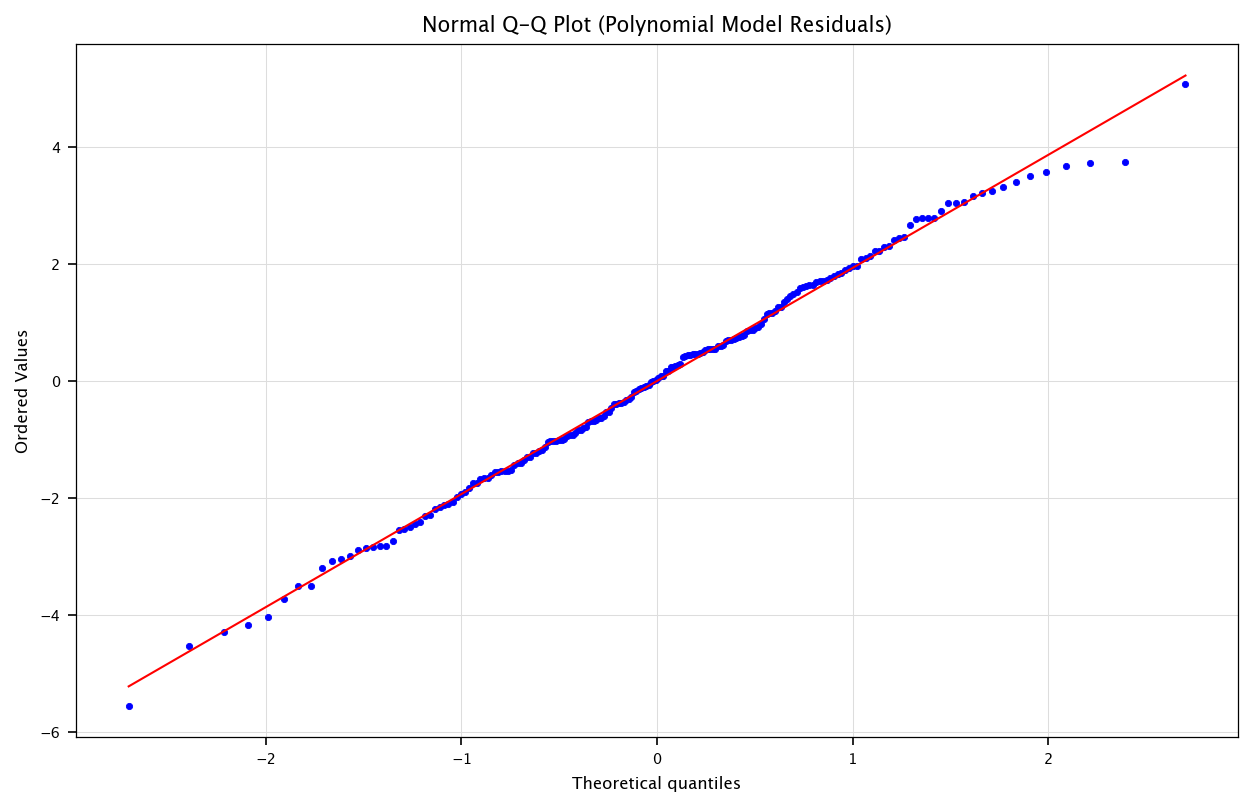
Interpretation:
If the polynomial model captures more structure, we may see less pattern in the residuals plot.
Alternatively, if the true relationship was already linear, polynomial terms might just overfit or remain insignificant.
3.7. RBF Expansion#
Polynomial feature expansion is a powerful tool to introduce non-linearity into a linear regression model, but it has several limitations:
Feature explosion: As the polynomial degree increases, the number of new features grows exponentially, making models computationally expensive and prone to overfitting.
Global transformations: Polynomial terms like \(X^2, X^3\) affect the entire input space, meaning that small changes in \(X\) have a large impact everywhere, which might not always be desirable.
Poor handling of local variations: Polynomial functions are not ideal when the relationship between \(X\) and \(y\) has local variations or is non-smooth.
This is where Radial Basis Function (RBF) expansion can be useful.
3.7.1. What is RBF Expansion?#
RBF expansion maps the original features into a higher-dimensional space using functions that respond locally to the input values.
Instead of using polynomial transformations like:
We use random Fourier features to approximate an RBF kernel, generating transformed variables like:
where \( W \) is a random weight matrix sampled from a Gaussian distribution.
3.7.1.1. Why Use RBF Instead of Polynomial Expansion?#
Better for local variations: Unlike polynomials, RBFs can capture localized structures in data.
Fixed feature size: The number of transformed features is independent of the input size, making it computationally efficient.
Good for high-dimensional data: Works well when the input space is high-dimensional because it avoids feature explosion.
3.7.2. Implementing RBF Expansion with Random Fourier Features#
We use sklearn.kernel_approximation.RBFSampler to generate random Fourier features that approximate the RBF kernel.
from sklearn.kernel_approximation import RBFSampler
rbf = RBFSampler(gamma=0.05, n_components=50, random_state=123)
X_rbf = rbf.fit_transform(df[['X1','X2','X3']])
print("RBF-transformed shape:", X_rbf.shape)
# We'll do OLS with statsmodels for brevity:
X_rbf_sm = sm.add_constant(X_rbf)
model_rbf_sm = sm.OLS(df['Y'], X_rbf_sm).fit()
print(model_rbf_sm.summary())
resid_rbf = model_rbf_sm.resid
fitted_rbf = model_rbf_sm.fittedvalues
plt.figure(figsize=(10, 6))
plt.scatter(fitted_rbf, resid_rbf, alpha=0.5)
plt.axhline(y=0, color='green', linestyle='--')
plt.xlabel("Fitted values (RBF)")
plt.ylabel("Residuals")
plt.title("Residuals vs. Fitted (RBF)")
plt.grid("on")
plt.show()
RBF-transformed shape: (200, 50)
OLS Regression Results
==============================================================================
Dep. Variable: Y R-squared: 0.980
Model: OLS Adj. R-squared: 0.973
Method: Least Squares F-statistic: 146.9
Date: Tue, 16 Sep 2025 Prob (F-statistic): 5.70e-105
Time: 13:31:42 Log-Likelihood: -396.22
No. Observations: 200 AIC: 894.4
Df Residuals: 149 BIC: 1063.
Df Model: 50
Covariance Type: nonrobust
==============================================================================
coef std err t P>|t| [0.025 0.975]
------------------------------------------------------------------------------
const -43.4898 19.729 -2.204 0.029 -82.475 -4.505
x1 7.1364 11.512 0.620 0.536 -15.612 29.885
x2 8.9773 3.334 2.692 0.008 2.388 15.566
x3 2.6549 7.719 0.344 0.731 -12.598 17.908
x4 1.1046 1.872 0.590 0.556 -2.595 4.804
x5 137.0639 46.449 2.951 0.004 45.280 228.848
x6 16.5251 11.039 1.497 0.137 -5.288 38.338
x7 -3.4503 4.473 -0.771 0.442 -12.288 5.388
x8 2.9028 3.919 0.741 0.460 -4.842 10.648
x9 -0.5036 6.801 -0.074 0.941 -13.942 12.934
x10 16.0558 15.230 1.054 0.294 -14.040 46.151
x11 24.7962 12.423 1.996 0.048 0.249 49.344
x12 59.4056 7.430 7.995 0.000 44.723 74.088
x13 -6.8051 11.750 -0.579 0.563 -30.024 16.414
x14 12.4240 24.130 0.515 0.607 -35.258 60.106
x15 -19.3450 7.617 -2.540 0.012 -34.397 -4.293
x16 -266.9437 65.123 -4.099 0.000 -395.627 -138.260
x17 5.0042 4.000 1.251 0.213 -2.900 12.908
x18 11.1227 5.828 1.909 0.058 -0.393 22.639
x19 24.4491 13.325 1.835 0.069 -1.882 50.780
x20 -6.4866 3.810 -1.702 0.091 -14.016 1.042
x21 -136.7679 40.658 -3.364 0.001 -217.108 -56.428
x22 -0.5810 7.714 -0.075 0.940 -15.825 14.663
x23 29.9036 16.223 1.843 0.067 -2.153 61.960
x24 43.4672 31.745 1.369 0.173 -19.261 106.195
x25 -2.5586 1.587 -1.612 0.109 -5.695 0.578
x26 24.3295 50.242 0.484 0.629 -74.950 123.609
x27 24.6458 14.259 1.728 0.086 -3.530 52.821
x28 -9.9883 14.837 -0.673 0.502 -39.306 19.329
x29 98.4893 31.798 3.097 0.002 35.657 161.322
x30 -5.2150 10.521 -0.496 0.621 -26.004 15.574
x31 -2.7180 16.134 -0.168 0.866 -34.600 29.164
x32 2.4668 1.976 1.248 0.214 -1.438 6.372
x33 2.5672 2.217 1.158 0.249 -1.814 6.948
x34 200.9372 54.077 3.716 0.000 94.081 307.793
x35 42.1785 14.095 2.992 0.003 14.327 70.031
x36 -24.5715 128.680 -0.191 0.849 -278.845 229.702
x37 156.2145 31.866 4.902 0.000 93.246 219.183
x38 -7.9412 16.226 -0.489 0.625 -40.004 24.122
x39 -1.1294 1.594 -0.709 0.480 -4.279 2.020
x40 -225.6936 88.747 -2.543 0.012 -401.059 -50.328
x41 -12.5555 36.848 -0.341 0.734 -85.367 60.256
x42 -12.9924 9.099 -1.428 0.155 -30.972 4.987
x43 25.7314 13.007 1.978 0.050 0.029 51.433
x44 7.2633 15.228 0.477 0.634 -22.827 37.353
x45 -70.8756 20.960 -3.381 0.001 -112.293 -29.458
x46 -46.6215 172.329 -0.271 0.787 -387.147 293.904
x47 0.5652 3.121 0.181 0.857 -5.602 6.732
x48 -6.3771 10.449 -0.610 0.543 -27.025 14.271
x49 153.3197 46.325 3.310 0.001 61.781 244.858
x50 9.1846 5.433 1.691 0.093 -1.551 19.920
==============================================================================
Omnibus: 0.557 Durbin-Watson: 2.049
Prob(Omnibus): 0.757 Jarque-Bera (JB): 0.682
Skew: -0.041 Prob(JB): 0.711
Kurtosis: 2.726 Cond. No. 1.75e+03
==============================================================================
Notes:
[1] Standard Errors assume that the covariance matrix of the errors is correctly specified.
[2] The condition number is large, 1.75e+03. This might indicate that there are
strong multicollinearity or other numerical problems.
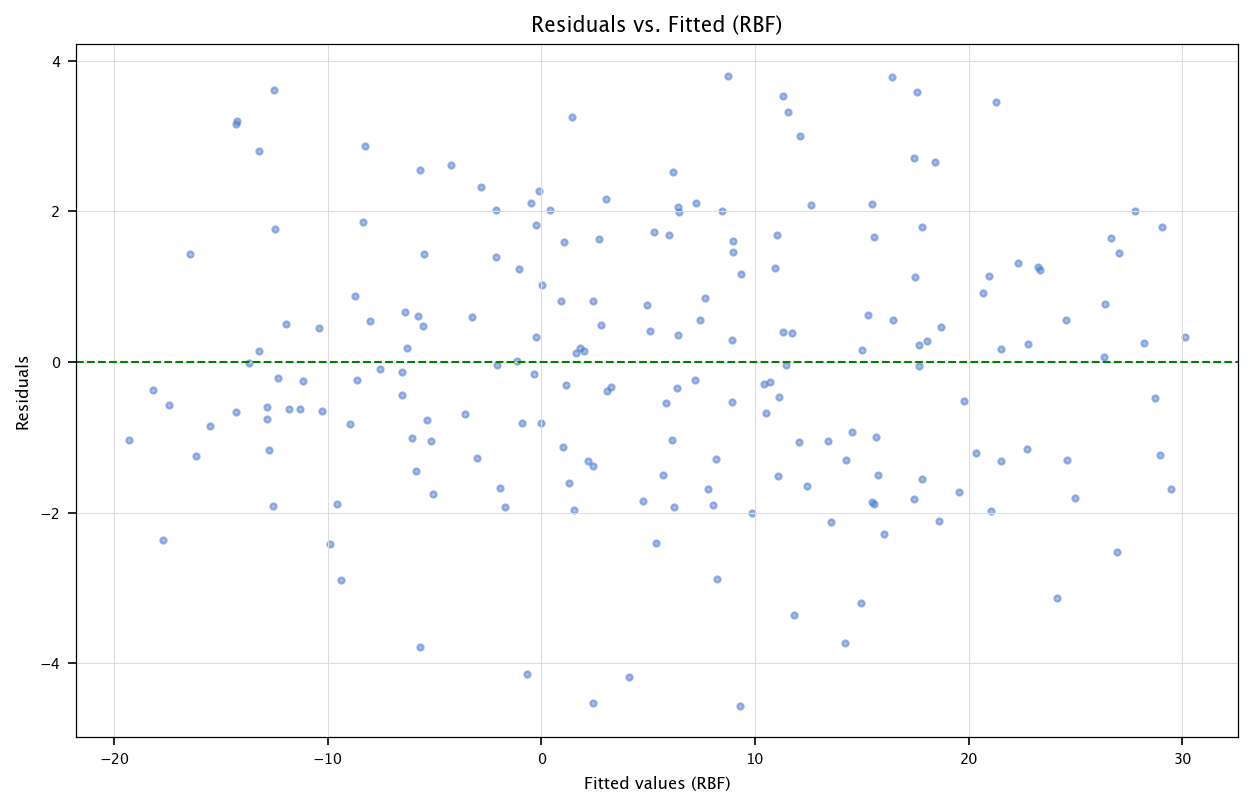
3.7.2.1. Comments#
Each RBF feature is basically a sinusoidal basis function in random projection space.
We could also attempt a manual approach:
\[ \hat{\beta} = (X_{\mathrm{rbf}}^\top X_{\mathrm{rbf}})^{-1} X_{\mathrm{rbf}}^\top y \]if we want to replicate the normal equation style.
The dimensionality (50) can be large, so be mindful of potential numerical issues and overfitting.
3.8. Ridge Regression#
For complex expansions (like polynomial of high degree or many RBF components), overfitting can happen. Ridge regression adds an L2 penalty:
3.8.1. Ridge Closed-form#
Ridge also has a known closed-form:
We’ll show a manual solution, then compare to scikit-learn. We’ll do it on the polynomial features for illustration.
alpha_ridge = 10.0
I_p = np.eye(X_poly_mat.shape[1]) # dimension p x p, where p = number of poly features + 1 (intercept)
# Usually we do not regularize the intercept, so we might set I_p[0,0] = 0.
# Let's do that to avoid shrinking the intercept:
I_p[0,0] = 0.0
XTX_ridge = X_poly_mat.T @ X_poly_mat + alpha_ridge*I_p
XTX_ridge_inv = np.linalg.inv(XTX_ridge)
XTy_ridge = X_poly_mat.T @ y_vec
beta_hat_ridge_manual = XTX_ridge_inv @ XTy_ridge
beta_hat_ridge_manual = beta_hat_ridge_manual.flatten()
print("Manual Ridge (polynomial) shape:", beta_hat_ridge_manual.shape)
pprint("\\text{Manual Ridge Coeffs}:", beta_hat_ridge_manual)
Manual Ridge (polynomial) shape: (10,)
from sklearn.linear_model import Ridge
ridge_sklearn = Ridge(alpha=alpha_ridge, fit_intercept=False)
# "fit_intercept=False" because we already included the intercept column in X_poly_mat
# We will manually set the intercept to match the first column or we can remove intercept from X_poly_mat.
ridge_sklearn.fit(X_poly_mat, df['Y'])
beta_hat_ridge_sklearn = ridge_sklearn.coef_
pprint("\\text{scikit-learn Ridge Coeffs}:", beta_hat_ridge_sklearn)
pprint("\\text{Difference (manual - sklearn)}:", (beta_hat_ridge_manual - beta_hat_ridge_sklearn))
They should be nearly identical (tiny floating discrepancies may occur).
3.8.2. Residual analysis for Ridge#
y_pred_ridge = X_poly_mat @ beta_hat_ridge_manual
resid_ridge = df['Y'] - y_pred_ridge
plt.figure(figsize=(10, 6))
plt.scatter(y_pred_ridge, resid_ridge, alpha=0.5)
plt.axhline(y=0, color='g', linestyle='--')
plt.xlabel("Fitted values (Ridge, polynomial)")
plt.ylabel("Residuals")
plt.title("Residuals vs. Fitted (Ridge)")
plt.grid("on")
plt.show()
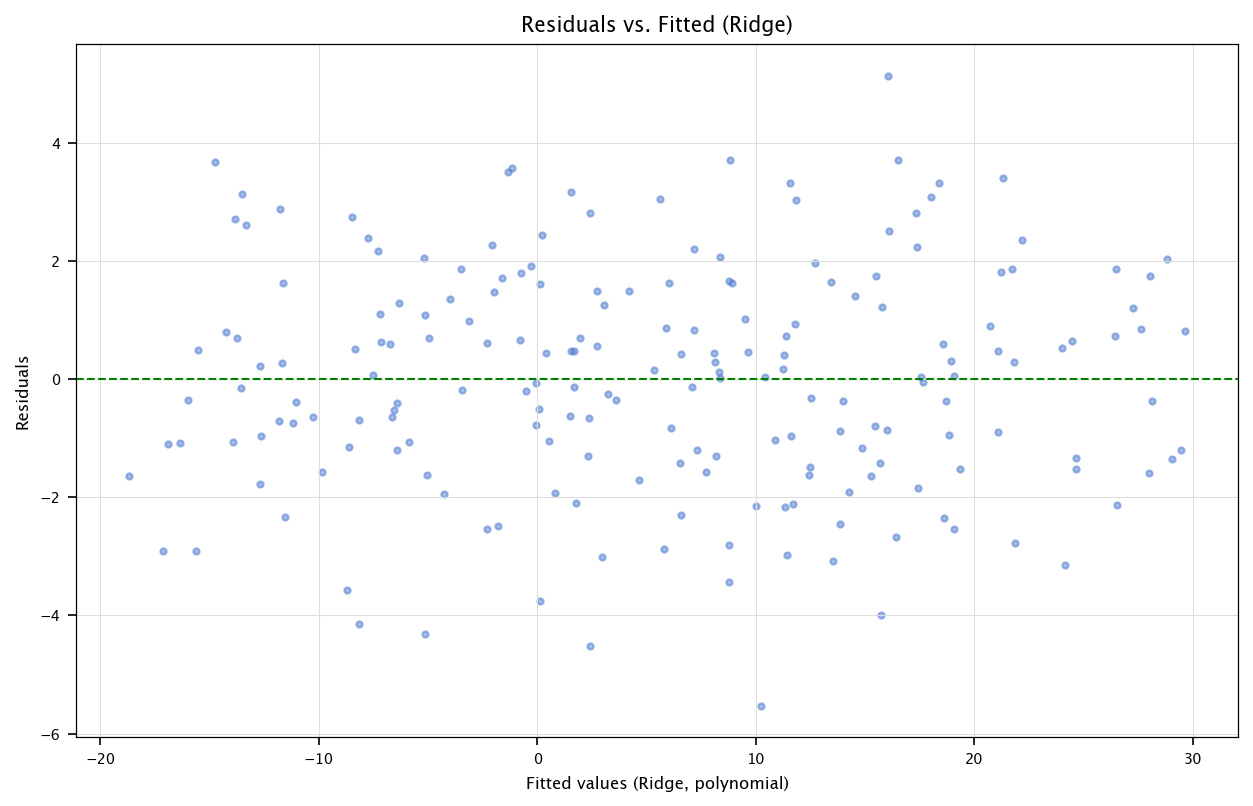
Remarks:
As alpha_ridge increases, the polynomial coefficients shrink more, typically reducing variance (but possibly increasing bias).
We can further use cross-validation to select alpha automatically or do a hyperparameter grid.
3.9. Conclusion#
This chapter has provided a comprehensive, hands-on exploration of linear models—starting from the manual derivation of the Ordinary Least Squares (OLS) estimator to the application of regularization techniques and feature transformations. Through synthetic data, we validated the accuracy of our estimators, examined residuals for assumption-checking, and used diagnostic plots to evaluate model fit.
We have seen how linear regression, while conceptually straightforward, remains a powerful modeling tool when used thoughtfully. The incorporation of polynomial and radial basis function expansions extends the expressive capacity of linear models, enabling them to approximate complex, non-linear relationships without abandoning interpretability.
We also introduced Ridge regression, which provides a principled approach to combat overfitting and multicollinearity, especially in high-dimensional settings. This regularized extension highlights a key transition in statistical learning: balancing model flexibility with generalization performance.
Ultimately, this chapter emphasizes not only how to implement linear models, but how to critically assess their assumptions and limitations. These foundational skills will be essential as we move on to more sophisticated models in the chapters ahead.
3.4.2.1. Comments#
Ideally, residuals vs. fitted values have no clear pattern and appear cloud-like.
The Q-Q plot should be fairly linear if they are normally distributed.
We can also check the standard deviation or run further tests (e.g., Shapiro-Wilk, Breusch-Pagan for heteroscedasticity) if desired.